- Link: python.plainenglish.io
- Author: Nitin Kushwaha
- Publication date: August 22, 2023
“Acknowledgment: Certain sections of the provided content are integral components of an assignment for the course ‘ID5030 Machine Learning for Engineering Applications’ at IIT Madras. These sections have been originally authored by me in my capacity as a Teaching Assistant for the course.”
In recent years, the landscape of computer vision (CV) has undergone a transformative shift with the advent of deep learning and convolutional neural networks (CNNs). Modern deep learning libraries like PyTorch, TensorFlow, and Keras have made the rapid implementation of various CV algorithms a reality. In this article, we embark on a journey through the fundamental realms of major CV tasks and their applications.

The outline of this post is as follows:
- Image classification
- Object Detection
- Image Segmentation
- Style Transfer
- GANs
Image classification
Image classification (also called image recognition) is probably the most widely used task in computer vision. In this task, we assume that images contain a main object and we want to automatically classify the object into pre-defined categories. The domain of image recognition encompasses both binary classification, where a two-category outcome is sought, and multi-class classification, which deals with categorizing objects into numerous distinct classes.”
Binary Classification
In the binary image classification, the goal is to segregate images into two distinct categories. For instance, consider the scenario of analyzing medical images, where the objective might be to determine whether a given image is indicative of normal tissue or malignancy. In this context, a ‘label=0’ might correspond to a normal image, while ‘label=1’ signifies a malignant one. The term ‘binary classification’ emerges from this dichotomy.
Below, we present an illustrative example of binary image classification, specifically focusing on image patches sourced from Histopathologic Cancer.
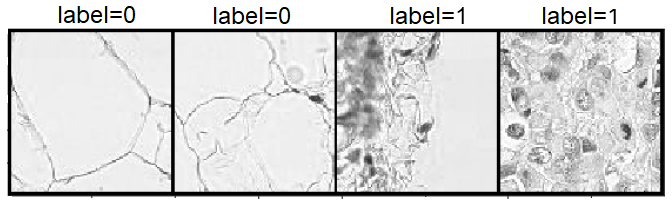
In the Histopathologic Cancer analysis, image patches serve as critical components for diagnosis. These image patches, accompanied by binary labels, play a pivotal role in the classification process. Within a given dataset, these patches — often numbering in the thousands for each patient — necessitate meticulous evaluation by clinicians. The potential impact of an automated tool capable of swiftly assigning labels to these myriad images is profound.
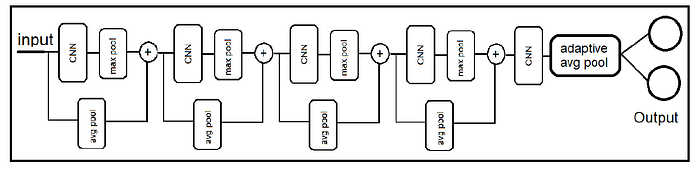
Deep learning models based on CNN are currently state-of-the-art to solve such problems. A block diagram of a CNN model is shown in the following figure.

You can learn to train and develop a binary image classification using PyTorch.
Multi-class Classification
On the other hand, the goal of multi-class image classification is to automatically assign a label to an image from a fixed (more than two) set of categories. Again, here the assumption is that the image contains a dominant object. For instance, the following figure shows a few samples from a dataset with 10 categories.

We may assign label 5 to dogs, label 2 to cars, label 0 to airplanes, and label 9 to trucks. As you may note, there may be more than one object in the images, however, the labels correspond to the dominant objects.
This task has also many applications in the industry, from autonomous vehicles to medical imaging, to automatically identify objects in images. you can learn to develop a pre-trained resnet18 model for multi-class image classification using PyTorch.
Object Detection
Object detection is the process of finding locations of specific objects in images. Similar to image classification, depending on the number of objects in images, we may deal with single-object or multi-object detection problems.
Single-object Detection
In single-object detection, we are interested to find the location of an object in a given image. In other words, we know the class of the object and only want to locate it in the image. The location of the object can be defined by a bounding box using four numbers, specifying the coordinates of the top left and bottom right corners.
As an example, the following image depicts the location of the fovea (a small pit) in an eye image using a green bounding box:
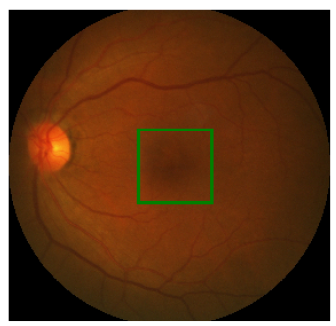
This task can be formulated as a regression problem to predict two/four numbers corresponding to the bounding box using a CNN model, as shown in the following figure.
You can learn to develop a single-object detection model in PyTorch.
Multi-object Detection
On the other hand, multi-object detection is the process of locating and classifying existing objects in an image. In other words, it is a simultaneous classification and localization task. Identified objects are shown with bounding boxes in the image, as shown in the following figure.

As you can see, each object is identified and labeled with a category label and located by a bounding box.
Two methods for general object detection include region proposal-based and regression/classification-based. A popular regression/classification-based approach named YOLOv3 is shown in the following figure.
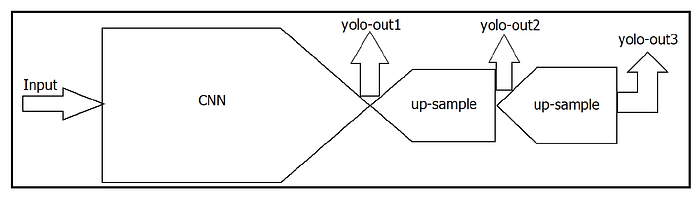
You can learn to develop the YOLOv3 algorithm for object detection using PyTorch.
Image Segmentation
Object segmentation is the process of finding the boundaries of target objects in images. There are many applications for segmenting objects in images. As an example, by outlining anatomical objects in medical images, clinical experts can learn useful information about patients.
Depending on the number of objects in images, we can deal with single-object or multi-object segmentation tasks.
Single-object Segmentation
In single-object segmentation, we are interested in automatically outlining the boundary of one target object in an image. The boundary of the object is usually defined by a binary mask. From the binary mask, we can overlay a contour on the image to outline the object boundary. As an example, the following figure depicts an ultrasound image of a fetus, a binary mask corresponding to the fetal head, and the segmentation of the fetal head overlaid on the ultrasound image:

The goal of automatic single-object segmentation will be to predict a binary mask given an image. Again, CNN models can be designed in the form of encoder-decoder to solve this task. A block diagram of an encoder-decoder is shown in the following figure.

you can learn to implement an encoder-decoder architecture for single-object segmentation using PyTorch. you can access the notebook form the link- https://colab.research.google.com/drive/1sXZ18grOnls9a_BsNkl2XOerLS5JE1nz?usp=sharing
On the other hand, in multi-object segmentation, we are interested in automatically outlining the boundaries of multiple target objects in an image. The boundaries of objects in an image are usually defined by a segmentation mask that’s the same size as the image. In the segmentation mask, all the pixels that belong to a target object are labeled the same based on pre-defined labeling. For instance, in the following screenshot, you can see a sample image with two types of targets: babies and chairs.

The corresponding segmentation mask is shown in the middle of the figure. As we can see, the pixels belonging to the babies and chairs are labeled differently and colored in yellow and green, respectively.
The goal of multiple-object segmentation will be to predict a segmentation mask given an image such that each pixel in the image is labeled based on its object class.
Style Transfer
You want to do something fun with images. Try neural style transfer. In neural style transfer, we take a regular image called the content image, and an artistic image called the style image. Then, we generate an image to have the content of the content image and the artistic style of the style image. By using the masterpieces of great artists as the style image, you can generate interesting images using this technique.
As an example, check out the following figure:

The image on the left is converted to the image on the right using a style image (middle).
In the style transfer algorithm, we keep the model parameters fixed and instead update the input to the model during training. This twist is the intuition behind the neural style transfer algorithm. A block diagram of the style transfer algorithm is shown in the following figure.
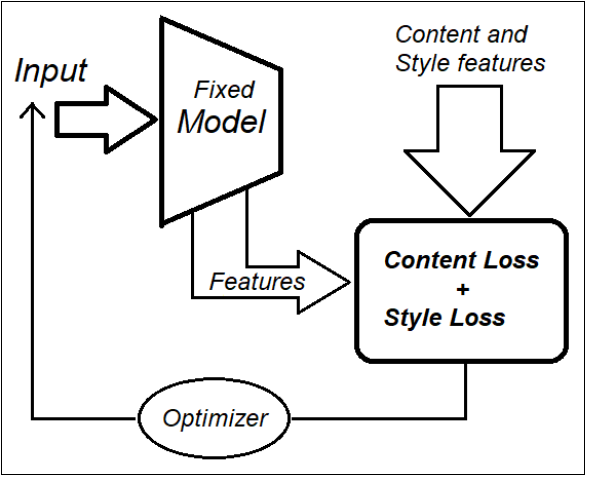
GANs
Do you want more fun with images? Try GANs. A GAN is a framework that’s used to generate new data by learning the distribution of data. The following figure shows a block diagram of a GAN for image generation.
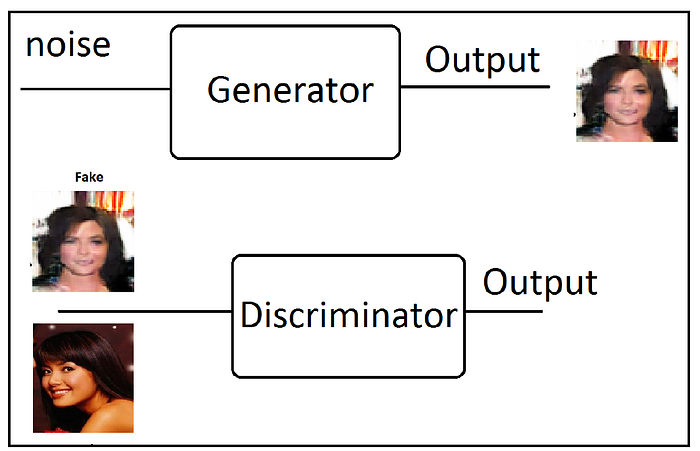
The generator generates fake data when given noise as input, and the discriminator classifies real images from fake images. During training, the generator and the discriminator compete with each other in a game. The generator tries to generate better-looking images to fool the discriminator, and the discriminator tries to get better at identifying real images from fake images.
Summary
In this post, I provided an overview of major computer vision tasks and how to solve them.