- Link: python.plainenglish.io
- Author: Jyoti Dabass, Ph.D
- Publication date: May 22, 2023
In the world of artificial intelligence (AI), there’s an ever-growing list of learning techniques that have emerged over time. From supervised learning to reinforcement learning, these methods help machines learn and make decisions based on data inputs. In this friendly introduction, we’ll provide a brief overview of twelve such techniques — including federated learning, meta-learning, contrastive learning, collaborative learning, representation learning, continual learning, and more! Whether you’re new to AI or looking to expand your knowledge, join us as we explore the exciting world of machine learning. Let’s dive in together!!

1. Reinforcement learning
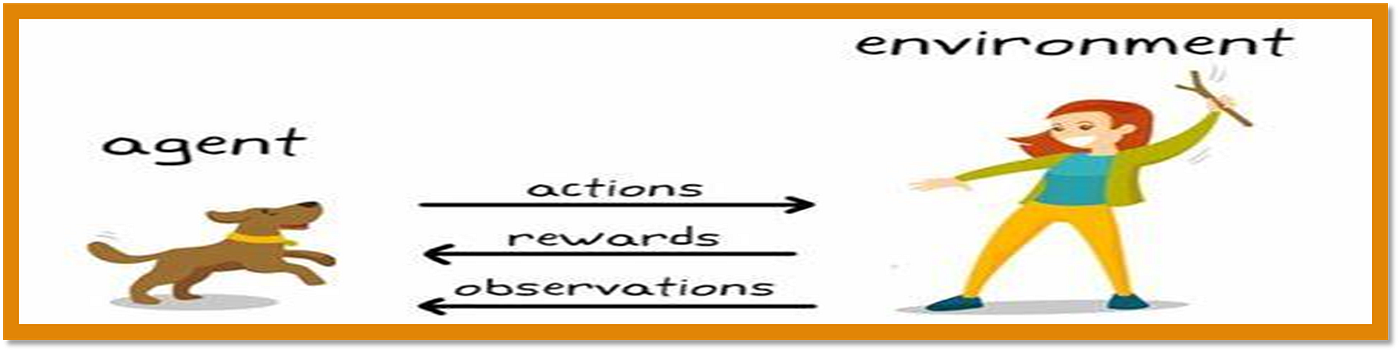
Reinforcement learning is a way for computers to learn how to behave in certain situations without being told exactly what to do. Imagine you want a virtual character to navigate through a maze and reach the exit. Instead of programming each step they take, you teach the character which steps are rewarding (like moving closer to the goal) and which ones result in punishment (like hitting a wall). Over many attempts, the character learns to choose the most rewarding path and eventually finds the quickest route to the finish line. That’s reinforced learning in a nutshell — teaching agents (virtual characters) to make smart choices by providing feedback based on consequences. Some popular applications of this technology include playing video games, controlling robots, optimizing business strategies, and improving medical treatments.
2. Federated learning
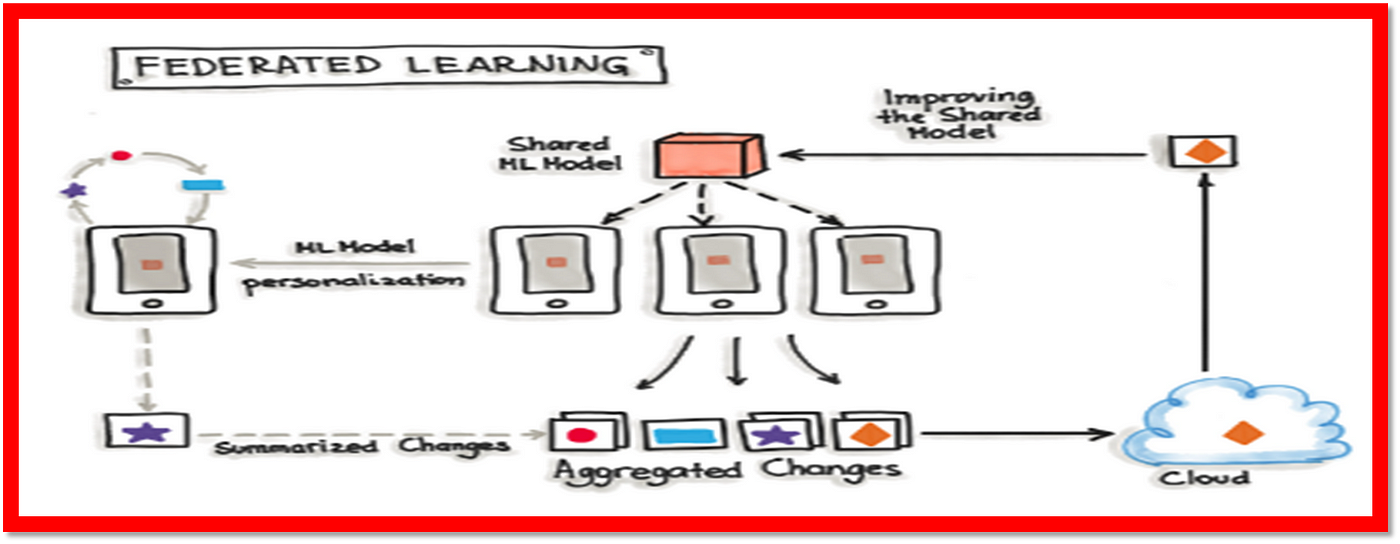
Federated learning is a technique that allows multiple devices to collaboratively train a shared machine learning model without sharing all their data. In other words, instead of sending sensitive information back and forth between central servers and individual devices, a portion of training occurs locally on each device while keeping the privacy and security of the users intact. For instance, imagine you own a fitness app with millions of users worldwide who use various types of wearable gadgets to track their physical activity. With federated learning, these users could contribute small amounts of encrypted data to refine a global prediction algorithm without revealing any personally identifiable information. As a result, everyone benefits from improved accuracy and efficiency without compromising confidentiality or network bandwidth. Applications of federated learning can be found across industries such as healthcare, finance, retail, and transportation.
3. Meta-learning
Meta-learning, also known as learning-to-learn, refers to a subfield of machine learning research that focuses on developing algorithms capable of efficiently adapting to new and unseen tasks using only a few examples. Unlike traditional supervised learning methods where models must be trained separately for each task, meta learners aim to discover patterns and transfer knowledge learned during previous similar tasks to quickly and accurately solve novel problems. For illustration, let’s say you build a model to recognize handwritten digits but then need to extend its capabilities to identify letters too. By implementing meta learning techniques, you may teach the model to recognize common features between digit and letter recognition, enabling faster adaptation to the latter rather than retraining completely. Besides enhancing the versatility and robustness of existing models, meta learning has promising implications for areas like lifelong learning, active learning, and resource-constrained scenarios where efficient utilization of resources matters.
4. Contrastive learning
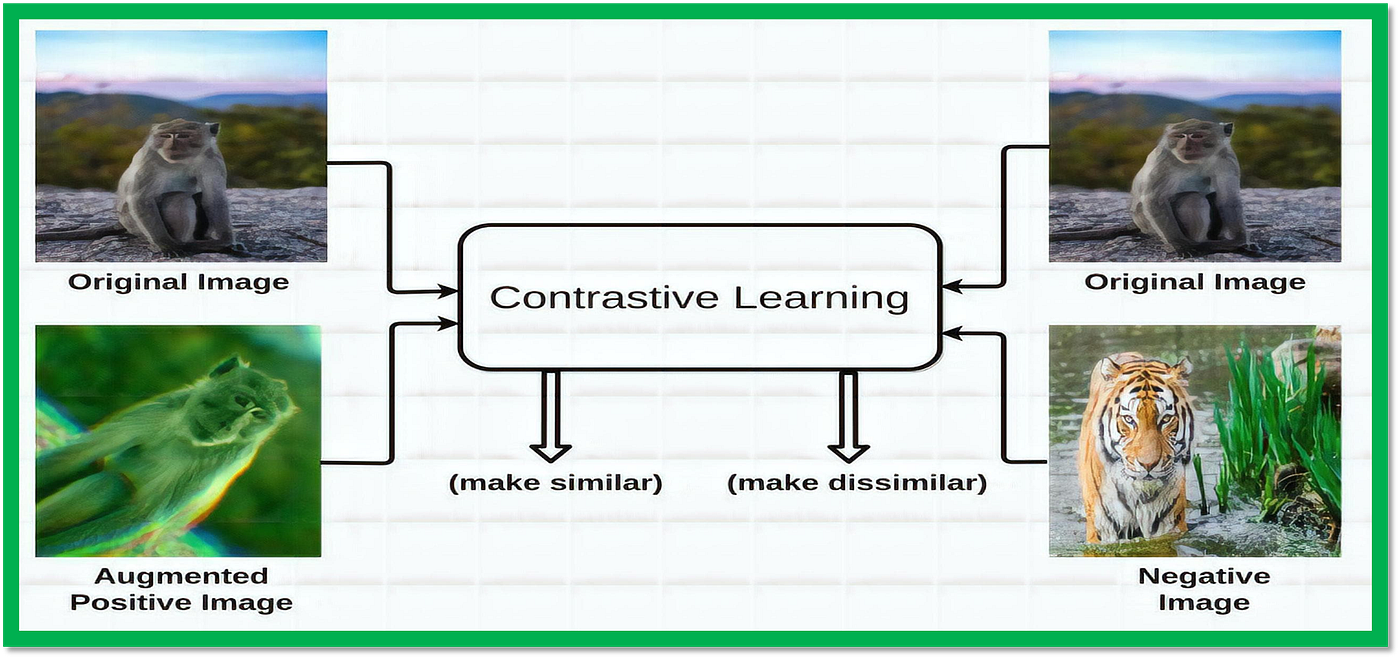
Contrastive learning is an approach used in self-supervised learning, a subset of machine learning that trains models without labeled data. The idea behind contrastive learning is to encourage a neural network to distinguish between pairs of inputs that share some similarities (“positive” pairs), while simultaneously minimizing the distance between dissimilar inputs (“negative” pairs). Through repeated comparisons and iterations, the model learns to extract meaningful representations from raw input signals, ultimately leading to better generalization performance on downstream tasks requiring classification, clustering, generation, or anomaly detection. A classic example of contrastive learning is visual feature extraction from large datasets of images, where the model aims to learn a representation space where semantically related images end up close together, while visually distinct pictures remain far apart. Other potential applications span speech, text, audio, and sequence processing domains.
5. Collaborative learning
Collaborative learning, also referred to as cooperative learning, describes the process by which multiple individuals work jointly towards achieving a common objective by sharing knowledge, skills, perspectives, and feedback among themselves. This concept applies not just to humans but also to machines, particularly when dealing with distributed datasets, complex decision making under uncertainty, and resource constraints. In collaborative learning for machines, a group of loosely coupled local models interactively exchange parameters or messages with one another via communication networks to produce a collective output that exceeds the capability of any single agent alone. To elaborate, think of a scenario where several hospitals possess diverse patient records that can assist in predicting disease outbreaks. Using collaborative learning techniques, the participating hospitals can collectively enhance the forecasting accuracy while preserving privacy and computational costs compared to transmitting full datasets to a central authority. Similarly, the methodology holds promise for various industrial applications ranging from financial trading, cybersecurity, social media analytics, and autonomous driving systems.

6. Representation learning
Representation learning is a crucial component of deep learning algorithms that enables them to automatically extract relevant features and patterns from raw input data through multiple layers of nonlinear transformations, rather than explicitly engineering those features by hand. This approach empowers models to learn more abstract and expressive representations at higher levels of abstraction, thereby facilitating better generalization and adaptability to new, previously unseen inputs. Consider a convolutional neural network (CNN) applied to image recognition: Each layer learns increasingly sophisticated features, starting from basic filters detecting edges and corners in lower layers, progressing to combinations of features encoding texture, shape, and spatial layouts in subsequent layers, and finally, arriving at high-level concepts capturing object categories in the final layers. These hierarchical feature maps enable CNNs to outperform human experts in certain benchmarks and pave the way for broader applications in fields like computer vision, natural language processing, and reinforcement learning. Overall, representation learning constitutes a critical breakthrough in modern machine learning, allowing us to tackle increasingly challenging problems with greater accuracy and efficiency.
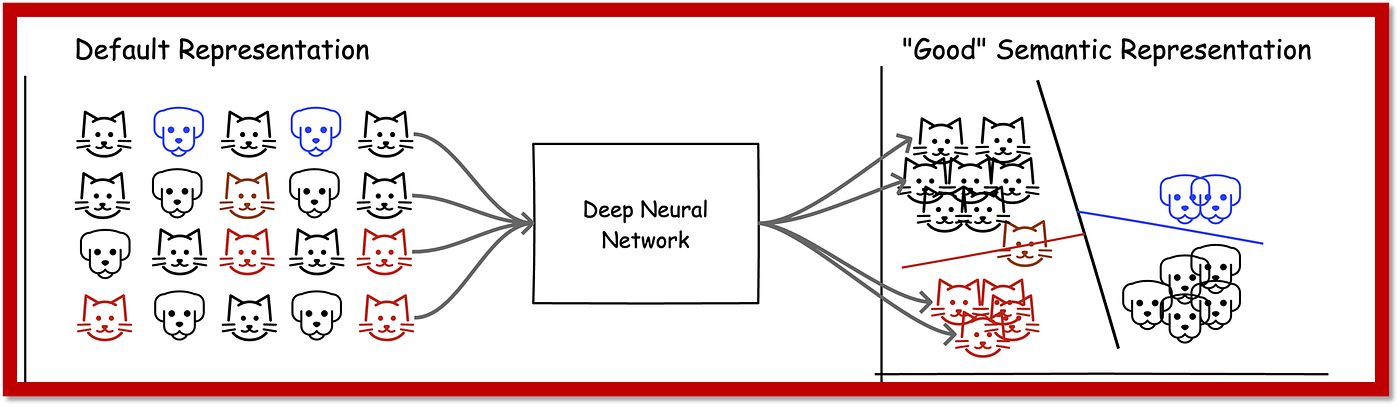
7. Continual learning
Continual learning, also called life-long learning, refers to the ability of an intelligent system to continuously acquire new knowledge and improve performance over time, even in the face of forgetfulness due to concept drift or catastrophic forgetting caused by learning new tasks or encountering rare events. While conventional approaches train a separate model for each specific task, continual learning aims to incrementally update the weights of an already deployed model without significant loss of prior knowledge or performance degradation. Imagine a mobile robot operating in dynamic environments, continually acquiring sensory inputs and updating its internal knowledge base to adapt to changing situations. Another application includes recommendation engines handling massive volumes of users and items, where continual learning allows incorporating user preferences and item interactions into the ranking algorithm without needing to retrain entirely. Continual learning poses challenges of credit assignment, memory management, and curriculum design, presenting exciting opportunities for future research and development.
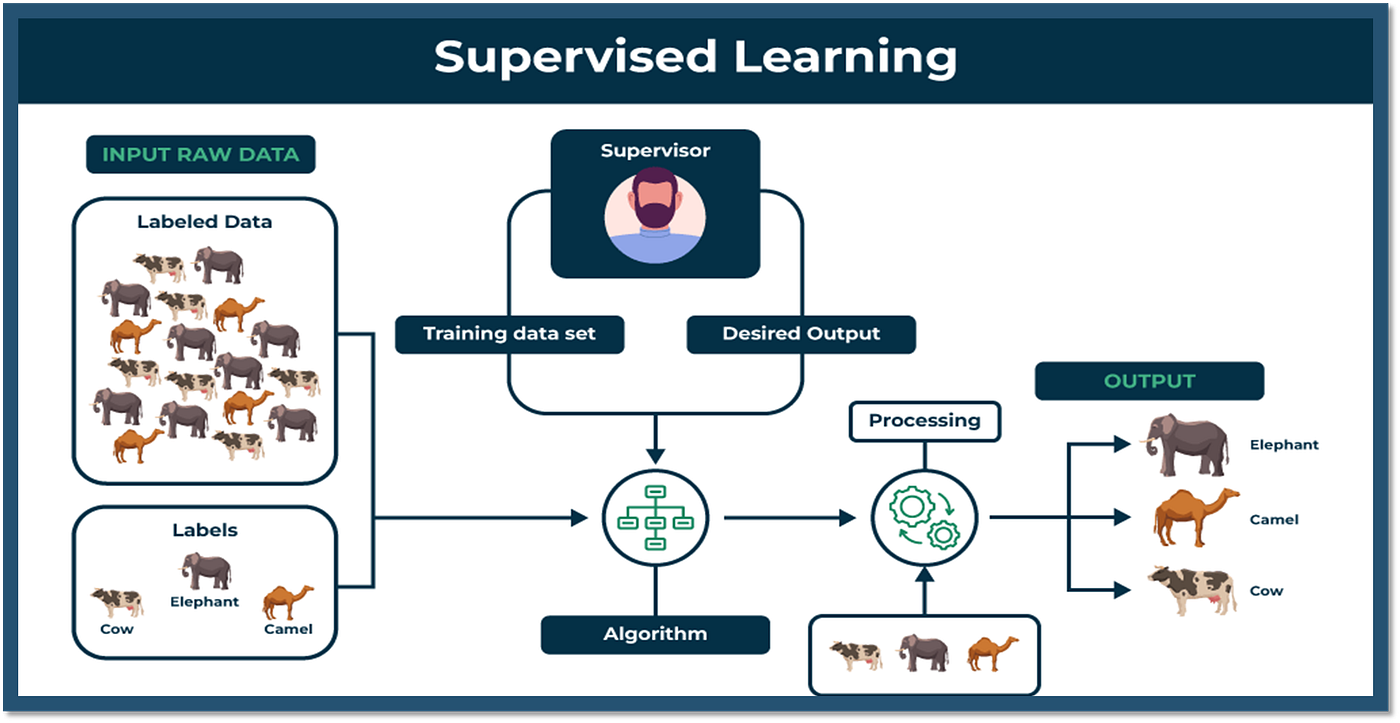
8. Supervised Learning
Supervised learning refers to a type of machine learning technique wherein a model is trained using labelled examples so it can accurately predict the output when provided with new but similar input. Essentially, the model “learns” what values should be associated with which sets of input variables, based on the relationships observed during training. For instance, consider a binary classification problem where we want our model to distinguish whether an email is spam or not based on features like sender name, subject line, etc. During training, we provide the model with thousands of emails, some marked as spam and others as legitimate mail. Through repeated iterations, the model adjusts its parameters until it can correctly classify new, unseen emails as either spam or ham with high confidence. In summary, supervised learning requires labelled data and focuses on making accurate predictions for unknown input based on learned associations. Other examples of supervised learning include regression analysis, speech recognition, and image segmentation.
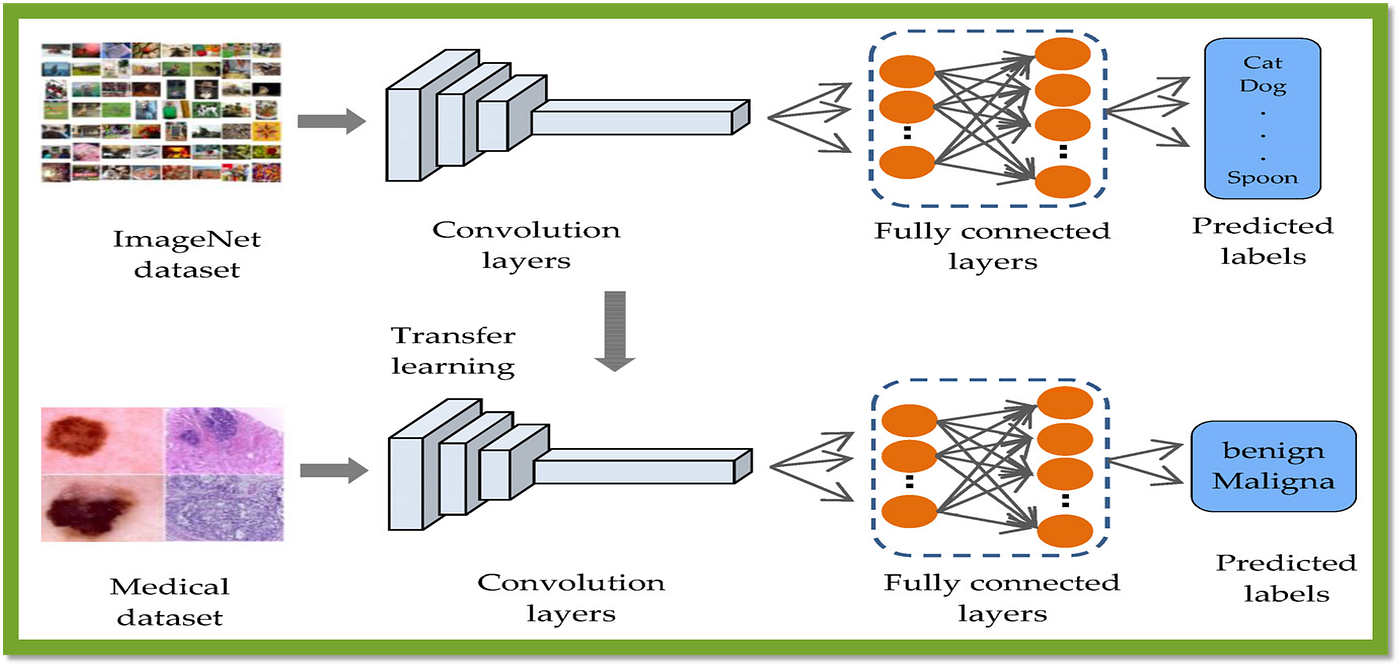
9. Transfer learning
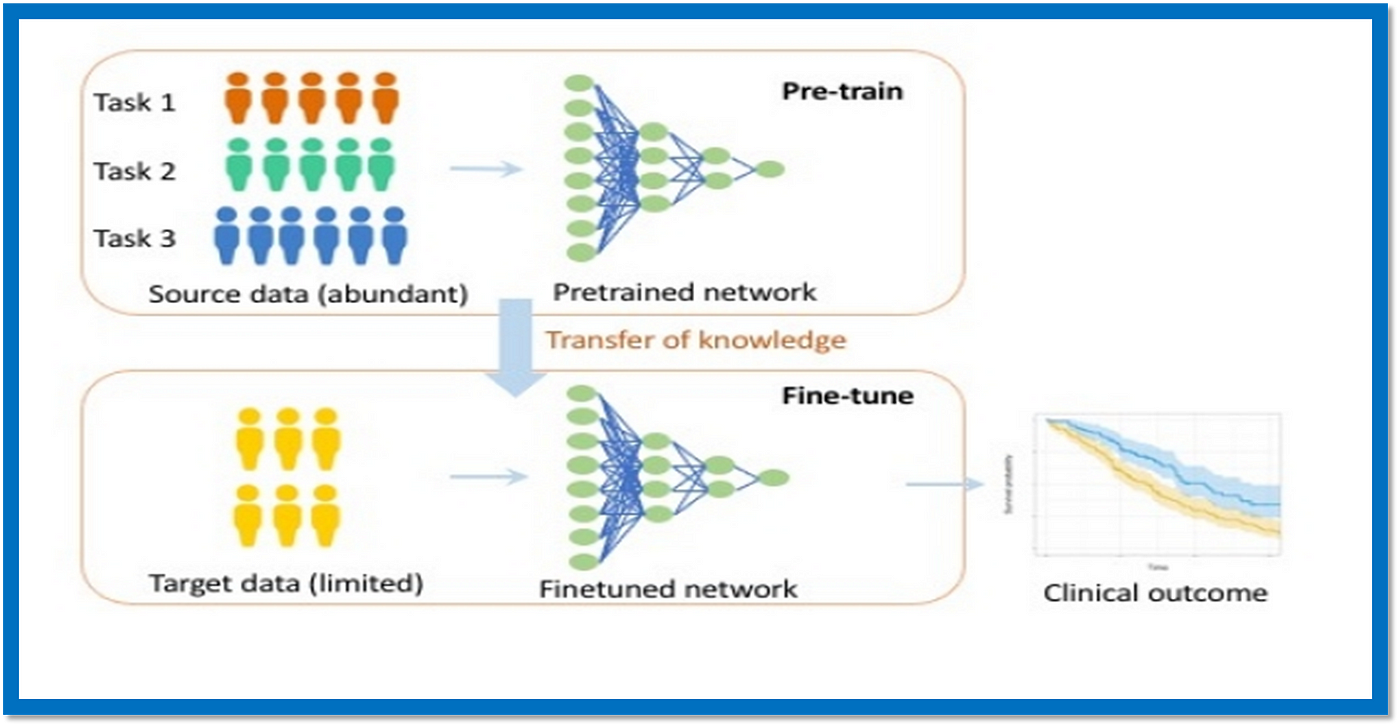
Transfer learning is a machine learning approach that leverages knowledge gained while solving one problem to help solve another related problem. Instead of building a new model from scratch, you take a pre-existing model trained on a large dataset and use it as a starting point to address a different but related challenge. This method saves time and resources since the majority of the heavy lifting has already been completed. To illustrate, imagine trying to build a model that recognizes dogs in images. Starting from scratch would require collecting a large set of dog pictures, splitting them into training, validation, and test sets, and then running multiple rounds of optimization to achieve satisfactory results. Alternatively, you could begin by adapting a general-purpose visual recognition network previously trained on millions of images covering a broad spectrum of objects, animals, and scenes. By retaining most of the pre-trained weights and applying customized fine-tuning strategies, you can quickly hone your model towards identifying canines specifically, thus accelerating the entire process considerably. Hence, transfer learning lets you leverage existing expertise to jumpstart your own projects without requiring vast quantities of fresh data or computing resources. It comes in handy across various domains, such as medical imaging diagnostics, autonomous driving, and multilingual text translation.
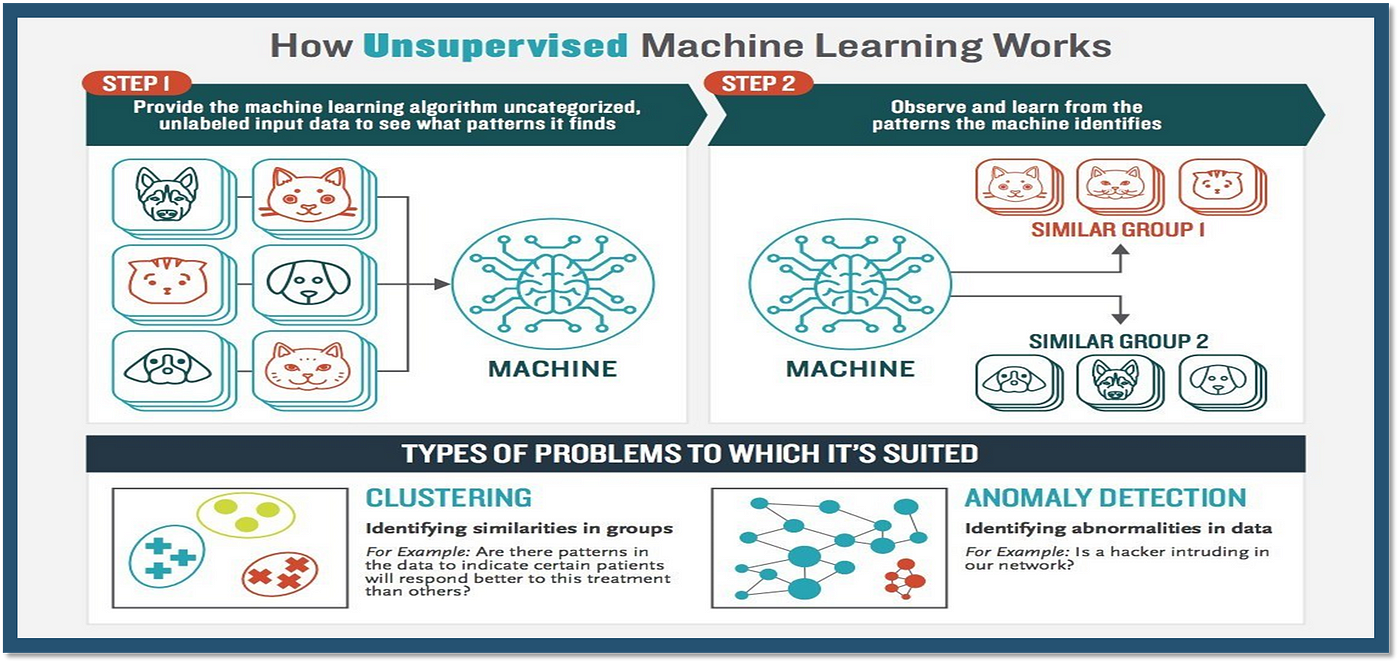
10. Unsupervised learning
Unsupervised learning is a form of machine learning that enables computers to identify patterns and structure within data that lack any explicit labels or instructions. Since these algorithms do not receive guidance in the form of correct answers, they learn independently by searching for inherent characteristics in raw inputs. For instance, let’s say you have a huge collection of customer transaction records at a retail store, and you want to group together customers who share similar buying habits. Without knowing anything about specific individuals beforehand, unsupervised learning algorithms can automatically detect clusters or communities of shoppers whose purchase histories exhibit striking similarities. They might also reveal latent variables or dimensions that underlie the original feature space, helping to compress or transform it more effectively. Beyond market basket analysis, unsupervised learning finds numerous practical applications, ranging from dimensionality reduction and anomaly detection to recommendation systems and natural language processing. Ultimately, it empowers us to extract meaningful insights and hidden correlations from unlabeled data sources that were previously difficult or impossible to analyze efficiently.
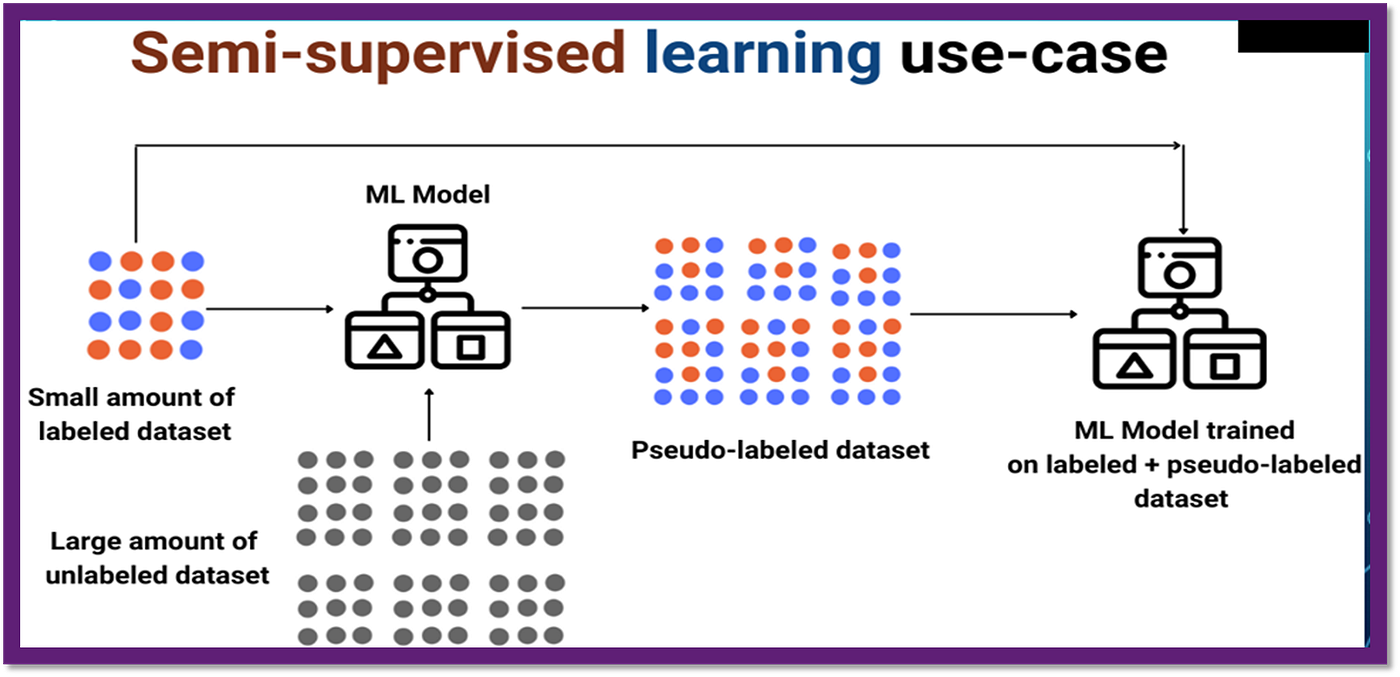
11. Semi-supervised learning
Semi-supervised learning combines elements of both supervised and unsupervised learning approaches to deal with situations where only a small amount of labeled data is available. The algorithm takes advantage of this scarce supervision to improve the performance of the model on larger volumes of unlabeled data through self-training. The basic idea behind semi-supervised learning is to utilize the information contained in unlabeled samples along with the little bit of labeled information to make better predictions. A common application of this technique occurs in computer vision, where a few hundred labeled images are used to train a convolutional neural network (CNN) for object detection or segmentation, supplemented by tens of thousands of unlabeled images to expand the scope of the model’s understanding. Another potential area of use is in scientific research, particularly in fields where experiments are expensive or dangerous, where researchers may only have access to a handful of labeled specimens while gathering many more unmarked ones. Here, semi-supervised learning can assist in filling out missing pieces of the picture gradually, leading to more comprehensive and reliable conclusions. Overall, semi-supervised learning strikes a balance between exploiting the power of labeled examples and exploring the full extent of raw data, enabling us to cope with practical scenarios featuring mixed levels of supervision more flexibly.
12. Active learning
Active learning is a subfield of machine learning that helps train accurate and efficient models using fewer labeled examples compared to traditional supervised learning techniques. Instead of presenting the entire dataset to be labeled, active learning lets the model choose which instances require human intervention and should be labeled.
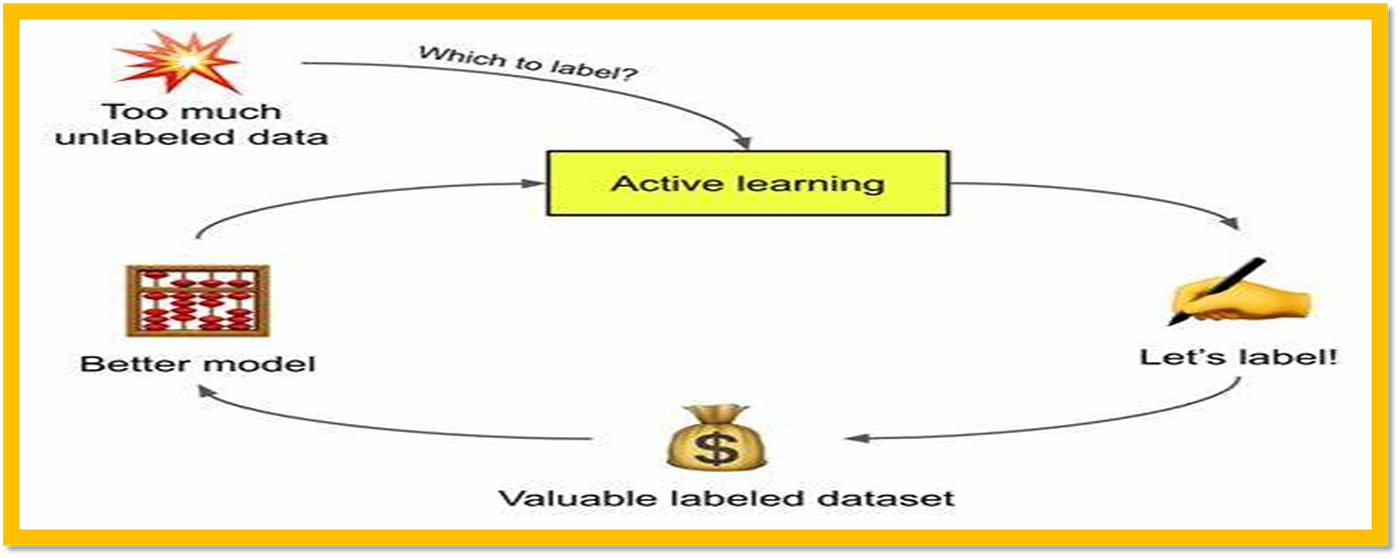
For instance, consider a scenario where we want to classify images into different categories like cars, buses, trucks, etc. If we apply traditional supervised learning, we would feed the whole dataset containing thousands or millions of images, each labeled by humans, into the model during training. However, if we use active learning, the model itself chooses a few unlabeled images from the original dataset based on uncertainty or ambiguity in their classification, sends them back to the human expert for labelling, and incorporates those labels into future iterations of training.
This way, the model gradually improves its accuracy while minimizing the amount of manual effort required for labeling. Overall, active learning enhances model efficiency, saves resources, and makes the most out of limited labeled data.