- Link:flyte.org
- Author: Samhita Alla
- Publication date: Oct. 11, 2023
An introductory guide to LLMs
As a machine learning engineer who has witnessed the rise of Large Language Models (LLMs), I find it daunting to comprehend how the ecosystem surrounding LLMs is developing. Every week, I come across new tools and techniques related to LLMs on my Twitter feed. It can be difficult to keep up with ways in which the LLM ecosystem is evolving. And if you’re just starting to use LLMs, the stream may seem to be moving too quickly to jump in!
The good news is that we’ve now reached a point where there are reliable and easy-to-use tools to work with LLMs. While more advanced tools will likely appear in the future, the current choices for fine-tuning models or making predictions are pretty impressive. They empower you to create some truly powerful applications.
In this post, I dive into the core principles of LLMs and the tools and techniques you’ll need to get started with LLMs.
What are LLMs?
A Large Language Model, as the name implies, refers to a model trained on large datasets to comprehend and generate content. Essentially, it’s a transformer model on a large scale. The transformer model itself is a neural network designed to grasp context and meaning through the analysis of relationships within sequential data.

Transformers are great for LLMs because they have two important features: positional encodings and self-attention.
Positional encodings help the model understand the order of words in a sequence and include this information in the word embeddings. Here’s a bit more about it from Brandon Rohrer’s article “Transformers from Scratch“:
“There are several ways that position information could be introduced into our embedded representation of words, but the way it was done in the original transformer was to add a circular wiggle.”

“The position of the word in the embedding space acts as the center of a circle. A perturbation is added to it, depending on where it falls in the order of the sequence of words. For each position, the word is moved the same distance but at a different angle, resulting in a circular pattern as you move through the sequence. Words that are close to each other in the sequence have similar perturbations, but words that are far apart are perturbed in different directions.”
Self-attention allows the words in a sequence to interact with each other and find out who they should pay more attention to. To help you understand this concept better, I’ve borrowed an example from Jay Alammar’s “The Illustrated Transformer” article:
“Say the following sentence is an input sentence we want to translate:”
‘The animal didn’t cross the street because it was too tired’
“What does ‘it’ in this sentence refer to? Is it referring to the street or to the animal? It’s a simple question to a human, but not as simple to an algorithm.”
“When the model is processing the word ‘it,’ self-attention allows it to associate ‘it’ with ‘animal.’”
Transformers utilize a powerful attention mechanism known as multi-head attention. Think of it as combining several self-attentions. This way, we can capture various aspects of language and better understand how different entities relate to each other in a sequence.
If you’re interested in a visual guide to understand LLMs and transformers, this resource is worth exploring.
What can LLMs do?
With LLMs, the possibilities are vast — from creating AI assistants and chatbots to engaging in conversations with your data and enhancing search capabilities.
AI assistants
The growth of LLMs has led to the development of many AI assistants, each designed for specific tasks like pair programming, scheduling and making reservations. Ongoing research aims to create a universal assistant capable of assisting with a wide range of tasks. Examples of such assistants include Pi and ChatGPT.
Chatbots
You can create chatbots tailored to specific tasks, like answering user or customer questions by fine-tuning them on custom data. For example, one of our community members has built a chatbot to address Flyte-related inquiries.
What’s more, you have the flexibility to develop chatbots that mimic the speech patterns of various personas, such as game characters or celebrities. Character.ai is an intriguing example.
Generation
LLMs are trained to generate the next piece of text given some input text. You can use them to write stories, create marketing content or even generate code. They’re great at understanding what comes next in a text, making them handy for all sorts of writing tasks.
Translation
An LLM excels at translation tasks, which are considered relatively straightforward for them. They can also handle more complex tasks like translating text into code. If you provide a user instruction to generate a code snippet in any programming language, an LLM should be able to generate the code for you. A popular example of such a model is Code Llama.
Summarization
With LLMs, you can create applications that automatically summarize long documents, research papers, and meeting notes and articles, making information more accessible.
Search
LLMs are great at grasping natural language queries. Unlike simple keyword-based searches, LLM-powered search engines like Google’s generative AI search and Perplexity AI offer more relevant and context-aware results. These advancements have revolutionized real-time search capabilities.
These use cases represent just the tip of the iceberg; LLMs offer many more possibilities, including personalization, recommendation systems, interactive fiction, gaming and much more.
Putting LLMs to the test
ChatGPT is the go-to choice for testing LLMs. However, if you’re a fan of open-source solutions like we are, you might want to explore HuggingChat. Additionally, there’s Google Bard and other open-source LLMs available on Hugging Face spaces. These can be used as hosted applications or accessed programmatically through the API.
You can find a list of open-source LLMs on Hugging Face in the Open LLM leaderboard. These models are assessed using the Eleuther AI Language Model Evaluation Harness framework, which evaluates generative language models across a wide range of tasks.
It’s important to note that not all chatbots or applications use the same LLM. ChatGPT employs the GPT-series models, HuggingChat currently utilizes the OpenAssistant LLaMa 30B SFT 6 model, and Google Bard is currently powered by the PaLM 2 model. It’s worth noting that these models can change over time as newer, more efficient models are continually trained on larger datasets and improved model architectures.
How do LLMs differ?
An important question we need to address: What’s the purpose of having multiple language models? It’s important to note that LLMs are still an active area of research, and we haven’t reached a point where we can rely on a single model for all tasks. Whether we will ever reach that stage remains uncertain. However, the community is actively working to discover the best models for various applications we intend to build upon and use.
The following are some key factors that contribute to the differences between LLMs:
Model architecture
LLMs can have different architectures depending on their objectives, computational resources and training tasks.
Data
The quality and amount of training data vary among models. PaLM 2, for instance, utilizes five times more data than its predecessor.
Parameter count
A higher parameter count indicates a more powerful model. For example, GPT-3 has 175 billion parameters. Meta’s Llama 2 includes models ranging from 7 billion to 70 billion parameters.
Training objective
While some LLMs excel at text completion tasks, others are designed for specific use cases. For instance, MosaicML introduced the StoryWriter model, developed to read and write fictional stories with extended context lengths (65K tokens). At inference time, it can go beyond 65K tokens.
Computational resources
Some LLMs are designed to be resource-intensive for better performance, while others prioritize efficiency for faster inference or when resources are limited. For example, Llama 2 can run on your Mac.
What are prompts?
A prompt is the input given by a user, and the model responds based on that input. A prompt can be a question, a command or any kind of input, depending on what’s needed for a particular use case. Copy
Copied to clipboard!
Classify the text into positive, negative or neutral.
Text: The movie isn’t that great.
Sentiment:This is a prompt that can be provided to an LLM to guide it. An LLM typically responds with ‘positive,’ ‘negative’ or ‘neutral’.


From the examples above, you can see that different LLMs create different results. This happens because of how they were trained, similar to how each of us has different opinions 🧠 about the sentiment that exact piece of text conveys.
Prompt format
A straightforward way to interact with an LLM is by offering an incomplete sentence and allowing the model to complete it. This approach aligns with the nature of pre-trained LLMs, which excel at text completion.Copy
Copied to clipboard!
Flamingos areWhen presented with this prompt, an LLM provides information about what flamingos are.

LLMs can do more than just complete text; they can summarize, generate code, solve math problems and more. Copy
Copied to clipboard!
<Q>: Two missiles speed directly toward each other, one at 9,000 miles per hour and the other at 21,000 miles per hour. They start 1,317 miles apart. Without using pencil and paper, calculate how far apart they are one minute before they collide.
<A>:
In this case, the format of the prompt is < Q > followed by < A >. However, the format can vary depending on the specific LLM you’re using and the response you’re aiming for. For instance, there’s a detailed guide on how to prompt Llama 2.
Creating clear and effective prompts is crucial to achieve the results you want, a process known as prompt engineering.
Prompt engineering
Prompt engineering is all about coaxing the model into a region of its latent space by manipulating the input prompt so the probability distribution of the next-tokens it predicts matches your intent. In simpler terms, it means guiding the model to generate the desired output.
There are many ways of doing this, such as providing examples of the kinds of outputs you want, instructing the model to write “in the style of” certain authors, using chain-of-thought reasoning, enabling the model to use external tools, and more.
Zero-shot prompts
A prompt that doesn’t provide specific examples for how the model should respond is called a “zero-shot prompt.” The flamingos prompt and the classification prompt are both examples of zero-shot prompts. Zero-shot prompts are effective in cases where the model understands the instruction.
Few-shot prompts
LLMs excel with zero-shot prompts but may struggle with complex tasks. Few-shot prompts, which include examples within the prompt, enable in-context learning. In this approach, the model learns from both the instructions and the provided examples to understand its task.


Chain of thought (CoT) prompting
CoT prompting encourages the LLM to provide explanations for its reasoning. Combining it with few-shot prompting can yield improved results for more intricate tasks that demand prior reasoning before generating responses.

The core concept behind CoT is that by presenting the LLM few-shot examples that include reasoning, it will subsequently incorporate the reasoning process into its responses when addressing prompts.
Let’s think step by step
Instead of including examples with reasoning in the prompt, you can achieve accurate answers by employing zero-shot prompting simply by adding “Let’s consider step by step” to the end of the question. This approach has been demonstrated in the Large Language Models are Zero-Shot Reasoners paper to yield reliable results.

In-context learning (ICL)
In-context learning (ICL) entails providing context within prompts, which can be in the form of examples (few-shot prompting) or additional information. This approach empowers pre-trained LLMs to assimilate new knowledge.

The categorization in this example can be easily understood — even at a glance, — because it represents a distinction between two- and four-wheelers. The LLM accurately categorizes based on the context provided in the prompt, showing its ability to infer. This approach can be extended to more-complex scenarios. For instance, a chatbot that interacts with data and incorporates context from provided documentation will be limited by the context window’s size because it restricts the information you can include in the prompt. Fortunately, you can overcome this limitation by using vector databases.
Vector databases
Vector databases store context vectors or embeddings. If you want to input documents into your LLM, you must first convert the text into vectors and store them in a vector database. Later, these vectors can be used to provide “relevant” context within prompts to the LLM. Relevancy, referred to as semantic search, involves finding similarities between input queries and documents, both of which are represented as vectors. This allows us to fetch selectively from the vector database and provide relevant documents to the LLM without overwhelming the prompt context window.

Examples of vector databases include Pinecone, ChromaDB and Weaviate.
The generic pipeline for semantic search and model prompting is as follows:
- Users input their query.
- The query is embedded using identical embeddings as document vectors.
- Semantic search retrieves the k-most similar documents from the vector database.
- The output of semantic search, along with the user query, is sent to the model to generate a coherent response.

LangChain is a popular tool to build context-aware applications on top of LLMs.
What is Retrieval Augmented Generation (RAG)?
The documents stored in the vector database may not provide up-to-date information for your LLM to answer accurately. This limitation arises because the model’s knowledge is restricted to the data it was trained on, which has a cutoff date. If you ask your model about recent events not included in its knowledge, it may produce inaccurate answers, a phenomenon often referred to as hallucination.
Retrieval Augmented Generation (RAG) addresses this issue by retrieving current context-specific information from an external database. This updated information is then fed into the LLM to generate accurate responses. RAG also enables the LLM to cite resources while generating responses.
How does RAG differ from regular in-context learning?
RAG can be conceptualized as an online, in-context learning method. The process of generating vectors, storing them in a vector database and updating the index occurs in real time. This effectively addresses the recency issue commonly observed in LLM applications. For instance, you can write your code to ensure that whenever there’s a data update, the indexing module upserts the data in the vector database.
RAG can be implemented through LangChain, HuggingFace, OpenAI and so on.
LLM parameters
When provided with a prompt, an LLM can generate a long list of potential responses. It operates like a prediction engine. However, in practice, LLMs typically provide a single output that represents the most likely response according to the model. The model calculates the probabilities of different words appearing in a response and returns only those words that meet the set parameters.
Model
The performance of a pre-trained LLM relies on its size: Larger models tend to produce higher-quality responses. However, bigger models increase costs and require more computational resources.
Temperature
Temperature influences the model’s creativity. Lower temperatures yield consistent and predictable results, while higher temperatures introduce randomness, resulting in more creative outputs. At a temperature of 0, the model always produces the same output. However, with higher temperatures, the model outputs words associated with varying probabilities.
Top-p and Top-k
Top-p selection involves choosing tokens from the highest-probability options; the sum of their probabilities determine the selection. For example, if p is set to 0.15, the model will select tokens like “United” and”’Netherlands” because their combined probabilities add up to 14.7%.

The lower the value of p, the more deterministic the responses generated by the model are. The general recommendation is to alter either temperature or top-p, but not both.
Top-k selection involves selecting the next token from the list of the highest k tokens, which are sorted by their probability. For instance, if k is set to 3, the model will choose from the top 3 options.

Number of tokens
Tokens serve as the fundamental units of text in LLMs. A token doesn’t always represent a single word; it can also encompass a group of characters. As a general rule of thumb, one token is roughly equivalent to four characters of English text.

The number of tokens in a model corresponds to the maximum number of input tokens the model can accept and the maximum number of output tokens it can produce. Typically, this number is set at 1,024, 2,048 or 4,096, but for some models, it can be even larger.
Stop sequences
Stop sequences can be employed to instruct the model to stop its token generation at a specific point, such as the end of a sentence or a list. It proves useful when you intend to stop token generation immediately upon encountering a stop sequence. This approach can be tailored to specific use cases or employed to reduce the cost of token generation.
Repetition penalty
Repetition penalty discourages the repetition of tokens that have appeared recently in the generated text. It encourages the model to produce more diverse tokens by reducing the likelihood of selecting tokens with higher scores.
When the repetition penalty is set to 1.0, there is no penalty applied. A value of 1.2 strikes a good balance between maintaining accuracy in generation and minimizing repetition, as described in this paper.
When to fine-tune?
Prompt engineering, with or without few-shot prompts and in-context learning, is suitable when the model needs data input. However, for scenarios requiring specific styles, patterns, specialized skills or internal model improvement, fine-tuning is a better choice. Fine-tuning involves updating model parameters through training on selected data, enhancing the model from within, while prompt engineering enhances the model externally. Fine-tuning is a more advanced technique, often requiring a substantial level of expertise in LLMs.

In the feature-based approach, we load a pre-trained LLM, generate output embeddings for the training set and use them as input features to train a classifier. In fine-tuning I, the output layers are pre-trained, keeping the LLM frozen. In fine-tuning II, all model layers are updated — that’s expensive and requires a lot more compute power.

Updating all layers (fine-tuning II) yields better performance than updating only the output layers (fine-tuning I). This can be seen in the performance plot from an experiment conducted by the blog post author, Sebastian Raschka. The graph shows performance plateaus when training the last two layers and transformer blocks, with no improvement in accuracy between the final stages. In other words, performing a full parameter fine-tuning becomes inefficient in terms of computation resources and time.
Parameter-efficient fine-tuning (PEFT)
PEFT (Parameter Efficient Fine-Tuning) reuses a pre-trained model to reduce computational and resource requirements. PEFT encompasses techniques that fine-tune a limited number of model parameters while preserving accuracy. Examples of PEFT techniques include prompt tuning and low rank adaptation (LoRA).
Prompt tuning
Prompt tuning falls between prompt engineering and fine-tuning. Unlike fine-tuning, it doesn’t modify the model parameters. Instead, it involves passing prompt embeddings along with each prompt sent to the model. Essentially, the model updates the prompt itself, creating what we call soft prompts. These soft prompts comprise embeddings, numeric representations derived from the larger model’s knowledge. In contrast to hard prompts, which are manually crafted with discrete input tokens, soft prompts cannot be directly viewed or edited as text.
Low rank adaptation (LoRA)
Another popular PEFT technique is LoRA, which facilitates fine-tuning specific adapters loaded into the model. LoRA achieves this by transforming weights into a lower-dimensional space, effectively reducing computational and storage demands.

Reinforcement learning with human feedback (RLHF)
In RLHF, a pre-trained model is fine-tuned via a combination of supervised and reinforcement learning. Human feedback is collected by ranking or rating various model outputs, creating a reward signal. These reward labels train a reward model, which, in turn, guides the LLM’s adaptation to human preferences.

The reward model can be initialized from a supervised fine-tuning model (SFT), where the model is fine-tuned through supervised learning. Then, the reward model calculates the loss and updates the pre-trained LLM using a form of reinforcement learning known as proximal policy optimization (PPO).

The Transformer Reinforcement Learning (TRL) library can be used to train transformer language models and stable diffusion models from SFT, reward modeling to PPO. It is built on top of the transformers library.
Optimization techniques for fine-tuning
To enhance fine-tuning efficiency, consider employing quantization and zero-redundancy optimization.
Note: This section is excerpted from Niels Bantilan’s blog post titled “Fine-Tuning vs. Prompt Engineering Large Language Models” on Union.ai.
Quantization reduces memory utilization
Quantization is the process of reducing the precision of numerical data so it consumes less memory and increases processing speed. However, lower precision leads to lower accuracy because less information is being stored within each layer. This doesn’t just apply to neural networks; if you’re a data scientist or ML engineer who has used Numpy, Pandas or any other numerical library, you’ve probably encountered float64, float32 and float16 data types. The numbers 64, 32 and 16, respectively, indicate how many bits are used to represent, in this case, floating point numbers.
Deep learning frameworks like PyTorch, TensorFlow and Jax, commonly provide utilities to do mixed-precision training; this lets the framework automatically cast the weights, biases, activations and gradients to lower floating-point precision (e.g. float16) when appropriate, and then cast them to higher precision representations (e.g. float32) when numerical stability matters (for instance in gradient accumulation or loss scaling). One library that may be of interest to fine-tuners is the bitsandbytes library, which uses 8-bit optimizers to reduce the memory footprint significantly during model training.

Zero-redundancy optimization shards and offloads model state
A few years ago, the only sort of data parallelism that you could easily leverage with deep learning libraries consumed a lot of GPU memory. If you had a machine with four GPUs, you could replicate the model four times, and if you could train a batch size of 8 on each GPU, you would obtain an effective batch size of 32.

The ZeRO paper, which is available via DeepSpeed and Pytorch’s FSDP implementation, enables you to shard the optimizer state, gradients and parameters across the available GPUs and CPUs in the training system. This is done in a layer-wise fashion, so only the model state required for a specific local forward/backward pass is replicated across GPUs. For example, if you’re training a neural net with three layers, the ZeRO protocol replicates the model state required for the forward pass of the first layer, freeing up memory once it obtains the activations. This is repeated in the forward passes for layers two and three. Finally, this process is applied to the backward passes, resulting in updates to the parameters of the model.

The ZeRO framework also allows for offloading of model states to CPU or NVMe where appropriate, which further reduces GPU memory consumption and improves training speed.
What is hallucination in LLMs?
A hallucination in an LLM occurs when the model generates text that seems plausible but is actually incorrect or nonsensical. While Google Bard, Perplexity AI, and Bing Chat show citations, they may reduce hallucinations to some extent but don’t fully eliminate them.

Why do LLMs hallucinate?
LLMs tend to hallucinate when they have an incomplete understanding of the prompt’s context. In such cases, they may make educated guesses based on learned patterns. Hallucinations can also be a result of incomplete or incorrect training data. Since LLMs rely on their training data rather than real-world information, their outputs may sometimes be irrelevant. However, techniques like Retrieval Augmented Generation (RAG) can be employed to incorporate real-time information and mitigate this issue.
How can you reduce hallucinations?
Hallucination can be desirable in certain scenarios, such as when creative responses are needed, like in story writing or marketing content creation. However, when accuracy and factual information are required, hallucination becomes undesirable.
Here are ways to mitigate hallucinations:
- Prompt engineering: By including more contextual information in the prompt, the language model gains a better understanding of the context and can generate more appropriate responses.
- In-context learning: When the model receives contextual information as part of the prompt, it has access to additional data that aids in generating accurate responses. A lack of context is a common cause of hallucinations.
- Controlled generation: Imposing sufficient constraints in the prompt can restrict the model’s freedom to produce hallucinatory content.
However, it’s important to note that hallucinations cannot always be completely eliminated. Models may still generate errors that are challenging to detect.
Running LLMs on local machines
Indeed, you heard correctly! You can run LLMs on your local machine to generate predictions. You can utilize Machine Learning Compilation (MLC) for LLM or employ llama.cpp for the same purpose.
MLC
MLC enables the native deployment of any LLM through native APIs with compiler acceleration. It offers support for the following platforms and hardware:
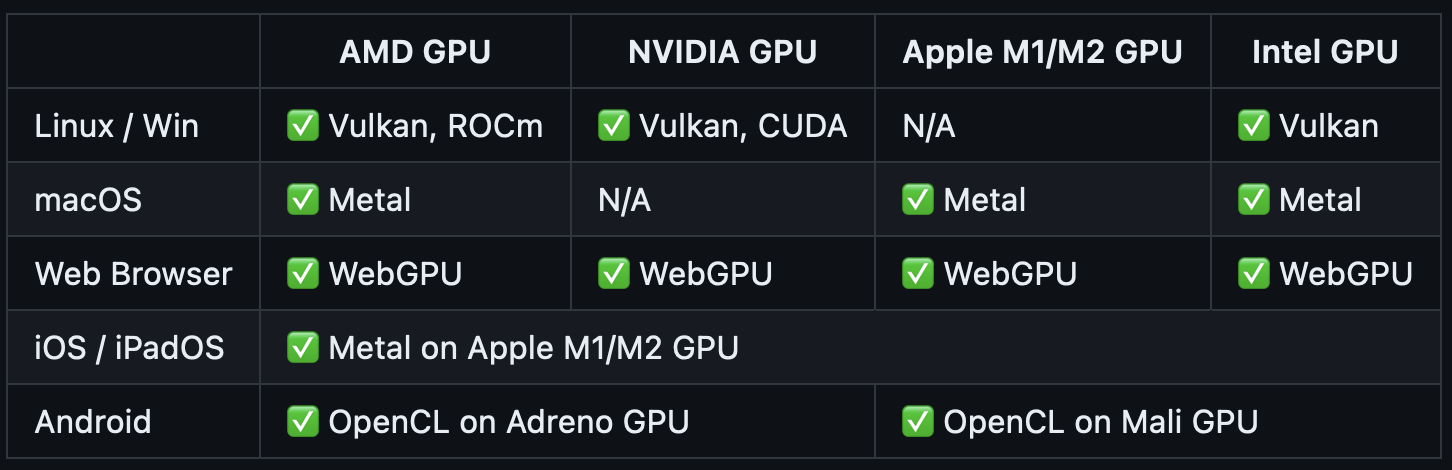
llama.cpp
llama.cpp empowers you to execute the Llama model using 4-bit integer quantization on a MacBook. It conducts the inference of the Llama model in pure C/C++.

Conclusion
This blog post introduced LLMs and discussed the various ways we could interact with them. It began with an overview of how LLMs had been developed and their applications. Following that, we delved into how LLMs were tested and why different types of LLMs were necessary, highlighting their differences.
We then explored the concept of prompts, which interact with the model and encourage it to generate accurate responses through various manipulations. Subsequently, we explored LLM parameters and examined some reasons for fine-tuning an LLM, along with optimization strategies to reduce computational and storage costs.
Finally, we addressed the issue of hallucination in LLMs and provided insights into running LLMs on local machines.
Fine-tuning and running LLMs in production
For those eager to explore further, you may want to know how to fine-tune an LLM with an orchestrated pipeline and perform low-latency, high-throughput inference.
Successful fine-tuning typically demands a significant amount of GPUs, RAM and memory resources, although it’s worth noting that some models can be fine-tuned on local machines. For instance, you can find guidance on fine-tuning Llama 2 on a local machine here. The specific resource requirements vary depending on the size of the model you’re working with.
Flyte enables the seamless integration of PyTorch Elastic Trainer, PEFT, quantization and various optimization techniques into your LLM pipeline for fine-tuning. Additionally, it offers the flexibility to implement strategies such as caching, recovery, checkpointing and running on spot instances. These features are part of the orchestration toolkit, which proves invaluable when optimizing resource allocation to lower costs and manage jobs more efficiently.
To delve deeper into the advantages offered by orchestrators like Flyte, you can explore further details here.
For inference, various tools like vLLM, CTranslate2, Ray serve and text generation inference can be employed to meet your specific needs.
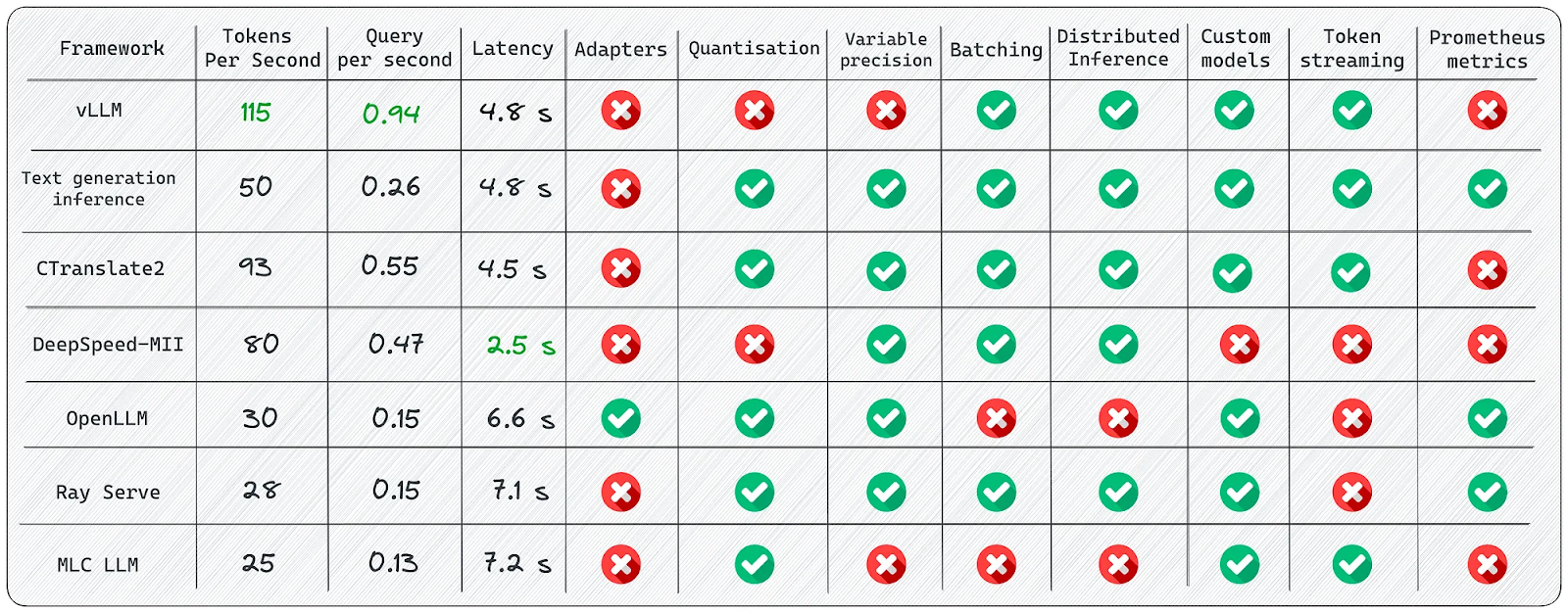
The world of LLMs is constantly evolving. As people venture into this field, we aim to ensure that all relevant and up-to-date information is included in this post. This is an ongoing effort, and we encourage you to share your thoughts and ideas with us on Slack, as well as your feedback on this post.